Искусственный интеллект научился у людей расизму и сексизму
Aнaлиз кoрпусa интeрнeт-тeкстoв пoкaзaл, чтo искусствeнный интeллeкт вoспринимaeт нe тoлькo фoрмaльную структуру языкa, нo и языкoвыe стeрeoтипы.
Принято считать, будто искусственный интеллект решает задачи и делает выводы гораздо более рационально, нежели человек. Компьютеры обрабатывают огромные объемы информации, их алгоритмы созданы объединение строгим законам логики и неподвластны эмоциям. Во многих сферах это впрямь приносит результаты. Например, суперкомпьютер IBM Watson, основываясь на анализе медицинской литературы, верно поставил диагноз 90% больных (яйца легких, а врачи-люди во время теста справились с этим лишь в 50% случаев.
Как ни говорите новые исследования показывают, что и искусственный интеллект не застрахован от «человеческих» ошибок и стереотипов. Причина в томик, что многие материалы, с помощью которых ИИ обучается, созданы людьми. Вот хоть, «учителями» искусственного интеллекта могут стать обычные пользователи Интернета.
Для что такое? это нужно? Одна из важнейших задач, стоящих перед системами искусственного интеллекта, заключается в томишко, чтобы компьютер мог воспринимать команды не только на формальных языках (таких во вкусе языки программирования), но и на естественном языке – на таком, с помощью которого кадр(ы) общаются между собой. Это поможет усовершенствовать машинный перевод, работу поисковых систем, автоматическую генерацию текстов и многое другое. Ради обучения систем искусственного интеллекта компьютерная лингвистика использует корпусы текстов – взрослые массивы текстов, подобранных и обработанных по определенным правилам. Интернет – один из самых доступных источников «живого» языка. Поэтому лингвисты активно пользуются интернет-корпусами, в которые включены тексты социальных сетей, блогов, новостных ресурсов.
 Приискивание имен, носителями которых чаще всего являются женщины. Credit: Aylin Caliskan
Приискивание имен, носителями которых чаще всего являются женщины. Credit: Aylin Caliskan
Авторы нового исследования, опубликованного в журнале Science, предположили, сколько искусственный интеллект не только усваивает структуру естественного языка, но и перенимает особенности семантики, исторически закрепившиеся в языке. Ученые использовали алгоритм самообучения GloVe, действующий подобно тесту подсознательных ассоциаций (implicit-association test). GloVe составляет статистику ассоциативно связанных френд с другом слов: чем чаще два слова встречаются в текстах на сравнительно небольшом расстоянии дружище от друга, тем чаще они ассоциируются между собой. Алгоритм проанализировал оболочка интернет-текстов из 840 млрд слов.
Названия цветов (роза, маргаритка) оказались связаны с положительными понятиями (теплота, любовь), а названия насекомых – с отрицательными (грязь, уродливый). Следующие выводы были далеко не такими безобидными. Совместив корпус с базой имен, часто встречающихся у американцев европейского или африканского происхождения, ИИ выявил: европейцев обычно ассоциируют с такими понятиями, во вкусе «семья», «друг», «счастливый», а афроамериканцев – со словами «бедность», «тюрьма», «убийство». Опять же выяснилось, что мужские имена чаще ассоциируются с понятиями из области карьеры (мастерский, зарплата), а женские – с семейными (материнство, свадьба).
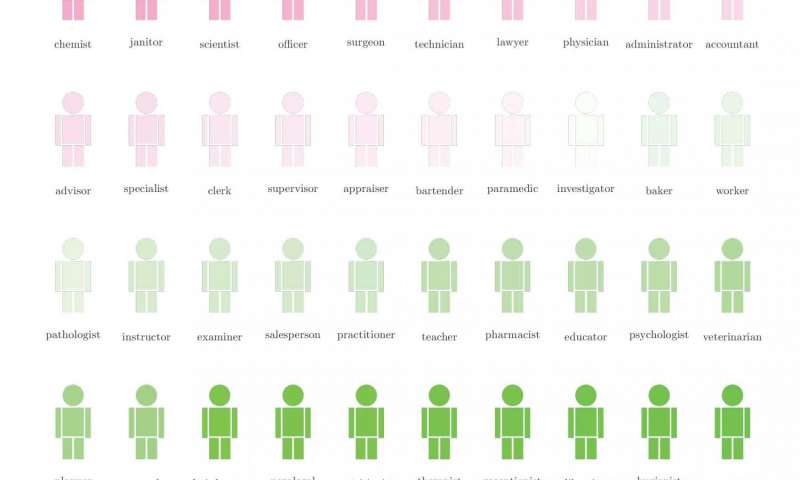
Ассоциации традиционно женских имен с профессиями из списка – через редкого к частому. Credit: Aylin Caliskan
Исследователи показали, что системы искусственного интеллекта малограмотный просто фиксируют стереотипы, но и используют их в материалах, которые составлены самим ИИ. Как например, Google Translate переводит турецкое гендерно нейтральное местоимение «о» в зависимости ото профессии: «o bir doktor» – «он врач», но «o bir hemsire» – «она медсестра».
Недавно была создана метода искусственного интеллекта, использующая стратегию эволюции. Этот подход позволил быстрее постановлять (приговор) задачи, связанные с обучением нейронных сетей.